JavaScriptRegExp - JavaScript regulārās izteiksmes
Регулярные выражения используются для поиска подстрок текста по
заданному шаблону (маске), состоящего из символов и метасимволов. Эта
технология получила свою популярность после включения её в состав
стандартных утилит Unix-систем, что привело к прорыву в электронной
обработке текстов.
Lasīt arī šeit : http://exsofter.ru/articles/48-javascript/296-regexpjs.html

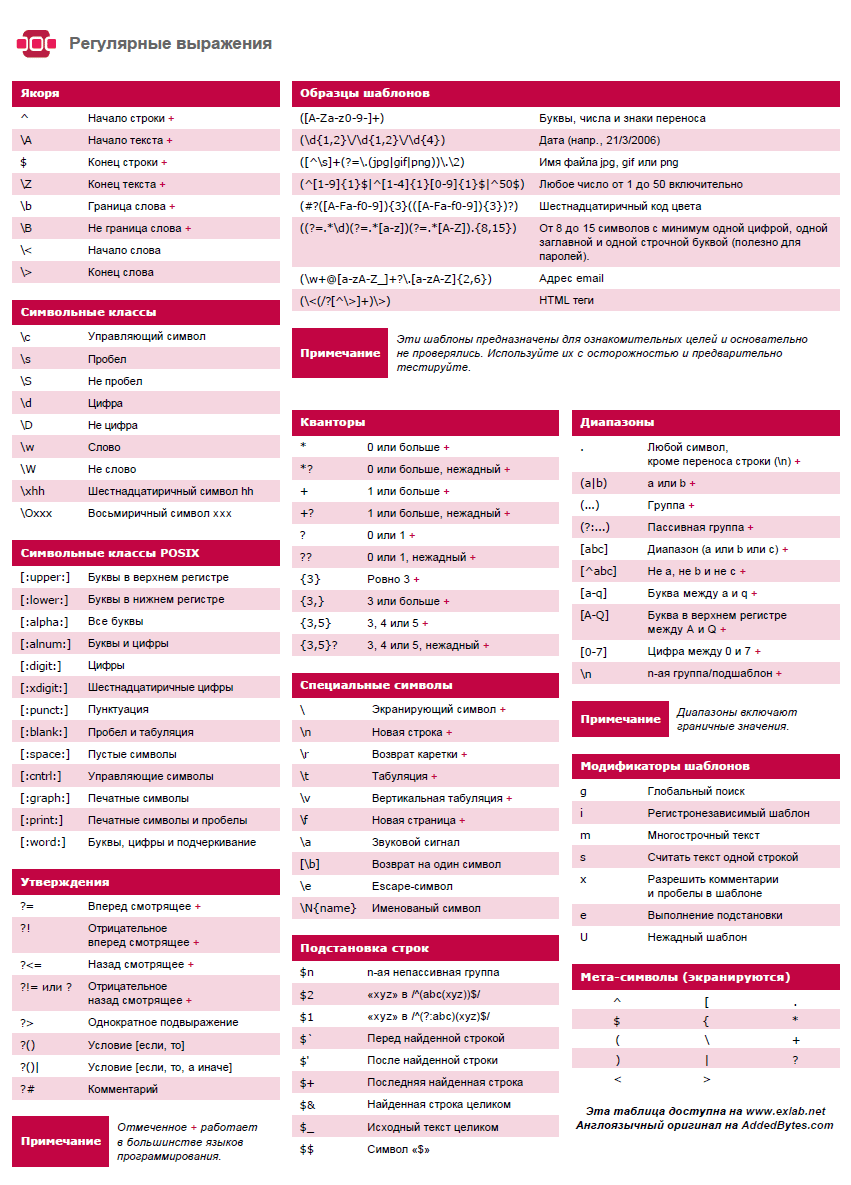
Создание
1 | // полная форма записи |
2 | var expr = new RegExp(pattern [, flags]); |
3 | |
4 | // сокращенная форма записи (литеральный формат) |
5 | var expr = /pattern/flags; |
Аргументы
- pattern
- Шаблон поиска (текст регулярного выражения).
- flags
-
Способы поиска по шаблону:
- g — глобальный поиск (обрабатываются все совпадения с шаблоном поиска);
- i — не различать строчные и заглавные буквы;
- m — многострочный поиск.
Порядок указания флагов не имеет значения.
Описание, примеры
Когда регулярное выражение создается при помощи конструктора new RegExp(…), необходимо помнить, что обратные слеши (\) должны экранироваться, например:
var expr = new RegExp('\\w', 'ig'); |
При использовании литерального формата, этого делать не нужно:
var expr = /\w/gi; |
Обе записи эквивалентны. Первый вариант может понадобится, если вам придется генерировать регулярное динамически.
Виды символов
В регулярных выражениях различают следующие виды символов:
Обычные символы
- A..z — английские буквы от A до z, строчные и заглавные;
- 0..9 — цифры;
- { } — фигурные скобки, кроме случаев, когда они составляют группу вида {n,m} (где n и m — числа) и её вариации;
- = — равно;
- < — меньше;
- > — больше;
- - — минус;
- , — запятая;
- и др.
Специальные символы
- ( ) — круглые скобки;
- [ ] — квадратные скобки;
- \ — обраный слеш;
- . — точка;
- ^ — степень;
- $ — знак доллара;
- | — вертикальная черта;
- ? — вопросительный знак;
- + — плюс.
Формирование регулярного выражения
При формировании шаблона поиска используется близкий к классическому PCRE синтаксис.
Спецсимволы в регулярном выражении
| Символ | Значение |
\ |
Для обычных символов - делает их специальными. Например, выражение /s/ ищет просто символ 's'. А если поставить \ перед s, то /\s/
уже обозначает пробельный символ.И наоборот, если символ специальный,
например *, то \ сделает его просто обычным символом "звездочка".
Например, /a*/ ищет 0 или больше подряд идущих символов 'a'. Чтобы найти а со звездочкой 'a*' - поставим \ перед спец. символом: /a\*/. |
^ |
Обозначает начало входных данных. Если установлен флаг многострочного поиска ("m"), то также сработает при начале новой строки.Например, /^A/ не найдет 'A' в "an A", но найдет первое 'A' в "An A." |
$ |
Обозначает конец входных данных. Если установлен флаг многострочного поиска, то также сработает в конце строки.Например, /t$/ не найдет 't' в "eater", но найдет - в "eat". |
* |
Обозначает повторение 0 или более раз. Например, /bo*/ найдет 'boooo' в "A ghost booooed" и 'b' в "A bird warbled", но ничего не найдет в "A goat grunted". |
+ |
Обозначает повторение 1 или более раз. Эквивалентно {1,}. Например, /a+/ найдет 'a' в "candy" и все 'a' в "caaaaaaandy". |
? |
Обозначает, что элемент может как присутствовать, так и отсутствовать. Например, /e?le?/ найдет 'el' в "angel" и 'le' в "angle."Если используется сразу после одного из квантификаторов *, +, ?, или {},
то задает "нежадный" поиск (повторение минимально возможное количество
раз, до ближайшего следующего элемента паттерна), в противоположность
"жадному" режиму по умолчанию, при котором количество повторений
максимально, даже если следующий элемент паттерна тоже подходит.Кроме
того, ? используется в предпросмотре, который описан в таблице под (?=), (?!), и (?: ). |
. |
(Десятичная точка) обозначает любой символ, кроме перевода строки: \n \r \u2028 or \u2029. (можно использовать [\s\S] для поиска любого символа, включая переводы строк). Например, /.n/ найдет 'an' и 'on' в "nay, an apple is on the tree", но не 'nay'. |
( |
Находит /(foo)/
найдет и запомнит 'foo' в "foo bar." Найденная подстрока хранится в
массиве-результате поиска или в предопределенных свойствах объекта
RegExp:$1, ..., $9.Кроме того,
скобки объединяют то, что в них находится, в единый элемент паттерна.
Например, (abc)* - повторение abc 0 и более раз. |
(?: |
Находит |
|
Находит /Jack(?=Sprat)/ найдет 'Jack', только если за ним следует 'Sprat'. /Jack(?=Sprat|Frost)/ найдет 'Jack', только если за ним следует 'Sprat' или 'Frost'. Однако, ни 'Sprat' nor 'Frost' не войдут в результат поиска. |
|
Находит /\d+(?!\.)/ найдет число, только если за ним не следует десятичная точка. /\d+(?!\.)/.exec("3.141") найдет 141, но не 3.141. |
|
Находит /green|red/ найдет 'green' в "green apple" и 'red' в "red apple." |
{ |
Где n - положительное целое число. Находит ровно n повторений предшествующего элемента. Например, /a{2}/ не найдет 'a' в "candy," но найдет оба a в "caandy," и первые два a в "caaandy." |
{ |
Где n - положительное целое число. Находит n и более повторений элемента. Например, /a{2,} не найдет 'a' в "candy", но найдет все 'a' в "caandy" и в "caaaaaaandy." |
{ |
Где n и m - положительные целые числа. Находят от n до m повторений элемента. |
[ |
Набор символов. Находит любой из перечисленных символов. Вы можете указать промежуток, используя тире. Например, [abcd] - то же самое, что [a-d]. Найдет 'b' в "brisket" и 'c' в "ache". |
[^ |
Любой символ, кроме указанных в наборе. Вы также можете указать промежуток. Например, [^abc] - то же самое, что [^a-c]. Найдет 'r' в "brisket" и 'h' в "chop." |
[\b] |
Находит символ backspace. (Не путать с \b.) |
\b |
Находит границу слов (латинских), например пробел. (Не путать с [\b]). Например, /\bn\w/ найдет 'no' в "noonday"; /\wy\b/ найдет 'ly' в "possibly yesterday." |
\B |
Обозначает не границу слов. Например, /\w\Bn/ найдет 'on' в "noonday", а /y\B\w/ найдет 'ye' в "possibly yesterday." |
\c |
/\cM/ обозначает символ Ctrl-M. |
\d |
находит цифру из любого алфавита (у нас же юникод). Испльзуйте [0-9], чтобы найти только обычные цифры. Например, /\d/ или /[0-9]/ найдет '2' в "B2 is the suite number." |
\D |
Найдет нецифровой символ (все алфавиты). [^0-9] - эквивалент для обычных цифр. Например, /\D/ или /[^0-9]/ найдет 'B' в "B2 is the suite number." |
\f,\r,\n |
Соответствующие спецсимволы form-feed, line-feed, перевод строки. |
\s |
Найдет любой пробельный символ, включая пробел, табуляцию, переводы строки и другие юникодные пробельные символы. Например, /\s\w*/ найдет ' bar' в "foo bar." |
\S |
Найдет любой символ, кроме пробельного. Например, /\S\w*/ найдет 'foo' в "foo bar." |
\t |
Символ табуляции. |
\v |
Символ вертикальной табуляции. |
\w |
Найдет любой словесный (латинский алфавит) символ, включая буквы, цифры и знак подчеркивания. Эквивалентно [A-Za-z0-9_]. Например, /\w/ найдет 'a' в "apple," '5' в "$5.28," и '3' в "3D." |
\W |
Найдет любой не-(лат.)словесный символ. Эквивалентно [^A-Za-z0-9_]. Например, /\W/ и /[^$A-Za-z0-9_]/ одинаково найдут '%' в "50%." |
\ |
где /apple(,)\sorange\1/ найдет 'apple, orange,' в "apple, orange, cherry, peach.". За таблицей есть более полный пример. |
\0 |
Найдет символ NUL. Не добавляйте в конец другие цифры. |
\x |
Найдет символ с кодом |
\u |
Найдет символ с кодом |
Пример: изменение формата строки
1 | var re = /(\w+)\s(\w+)/; |
2 | var str = "John Smith"; |
3 | var newstr = str.replace(re, "$2, $1"); |
4 | alert(newstr); // "Smith, John" |
Lasīt arī šeit : http://exsofter.ru/articles/48-javascript/296-regexpjs.html